閒聊
預期效果
透過Selenium成功開啟Dcard分頁(瀏覽器分頁),並用內鍵工具索取目前所有文章,將文章存在JSON檔案。
實作
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.dcard.tw/f')
這時候我們可以看看文章中是否有class元素可以讓我們爬取,確認好後就可以開始準備爬取了。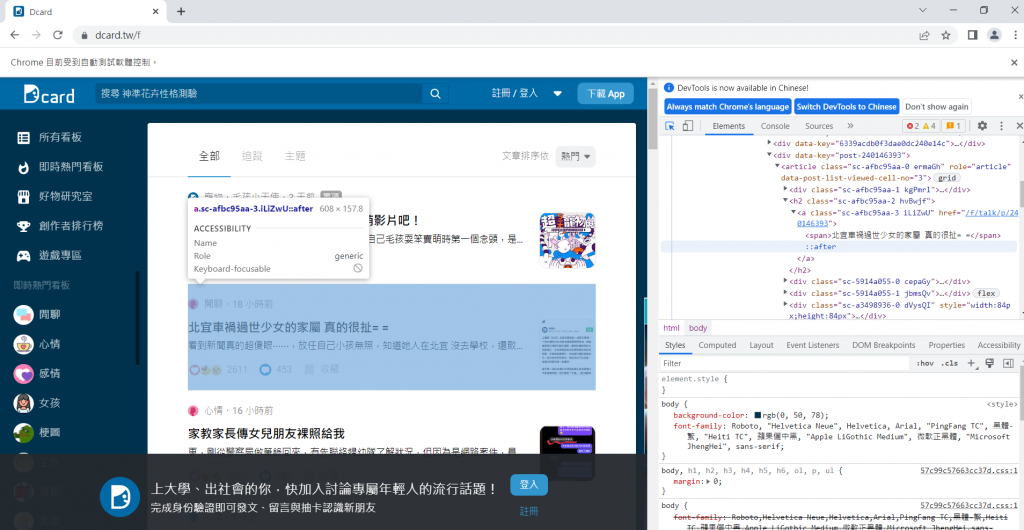
driver.find_element_by_class_name來定位,並且使用for-loop迴圈將回傳的list輸出。time的sleep來讓程式碼暫停一點,使文章載入完成。(避免因為還沒載入完成就抓不到元素的情況)append到總結果中。from selenium import webdriver
from time import sleep
if _name_ == '_main_'
driver = webdriver.Chrome()
driver.get('https://www.dcard.tw/f')
sleep(2) #讓程式碼暫停0.5秒
eles = driver.find_element_by_class_name('sc-afbc95aa-0')
for ele in eles :
result = {}
title = ele.find_element_by_class_name('sc-afbc95aa-2').text
href = ele.find_element_by_class_name('sc-afbc95aa-2').get_attribute('href')
subtitle = ele.find_element_by_class_name('sc-5914a055-0').text
result = {
'title' : title #print(title)
'href' : href #print(href)
'subtitle' : subtitle #print(subtitle)
}
results.append(result)
print(result)
driver.quit() #關閉瀏覽器
from selenium import webdriver
from time import sleep
import json
if _name_ == '_main_'
driver = webdriver.Chrome()
driver.get('https://www.dcard.tw/f')
sleep(2) #讓程式碼暫停0.5秒
eles = driver.find_element_by_class_name('sc-afbc95aa-0')
for ele in eles :
result = {}
title = ele.find_element_by_class_name('sc-afbc95aa-2').text
href = ele.find_element_by_class_name('sc-afbc95aa-2').get_attribute('href')
subtitle = ele.find_element_by_class_name('sc-5914a055-0').text
result = {
'title' : title #print(title)
'href' : href #print(href)
'subtitle' : subtitle #print(subtitle)
}
results.append(result)
print(result)
with open('Dcard-articles.json', 'w', encoding='utf-8') as f:
json.dump(results, f, indent=2,
sort_keys=True, ensure_ascii=False)
driver.quit() #關閉瀏覽器
結語
今天試著用Selenium爬取了Dcard的文章,並且儲存起來。
明天要來試試看Selenium著名的功能:模擬使用者使用狀況。
明天!
【Day 21】在Dcard上自動向下捲動吧!(實戰Selenium 1/2)
參考資料
Selenium 函式庫

